
Map <- AbstractMap <- HashMap
基本过程描述:HashMap里有一个数组,计算hashcode,存入对应的数据位置。对于重复的元素采用链地址法,装在同一个数组下标的桶当中。
TreeifyThreshold为8,当树元素个数>=8的时候,平均查找长度为3。而如果是链表,则平均查找长度为4,这是转换成红黑树才有必要。
树化的条件是:桶中链表的长度大于8,并且数组的长度大于等于64。
UnTreeifyThreshold为6,主要是为了减少频繁树化、去树化的过程。
桶数组的个数为啥是2^n^,hash通过取模运算定位到桶数组的下标hash%length,在计算机中位运算的效率更高。满足2^n^的时候 hash%length== hash & (length-1) 可以很快的获取到需要存储的位置。同时length-1 == 2^n^-1,length-1的每一位都是1,可以很均匀的将hash分布在桶数组中,减少hash碰撞。
1) 用取模算法定位下标,当length == 2^n^ 的时候,可以用
hash & (length-1)更快的计算出对应的index。2) 2^n^ - 1 的每一位都是1,可以是散列更分散。
resize:每次resize都扩容为两倍。申请一个两倍的桶数组(保证2^n),将原先的记录逐个重新映射(重新计算hash)到新的桶里面,然后将原先的桶逐个置为null使得引用失效。 (HashMap之所以线程不安全,就是resize这里出的问题。)
HashMap线程不安全
WHY:几种情况
put的时候,A、B两个线程,在Aput的时候获得了桶链表结尾的地址,这时候A时间片到了,B线程执行也需要put,也获取了最后的地址,将新的Node<K,V>插入到末尾。当A开始执行,他拥有的末尾地址还是旧的地址、不是最新的末尾节点。A进行put的时候就把B的数据给覆盖了。(1.8及之后的不安全所在)
get的时候会导致cpu100%。在resize的时候会造成环形链表。(1.8以前的,1.8及之后改用尾插入链表法,不会产生这个问题)
resize的时候会导致数据丢失(1.8以前的)
为什么0.75
threshold = loadFactor * capacity = 0.75 * 16 = 12 // 默认加载因子和容量,在达到12容量就会扩容
HashMap默认加载因子为什么选择0.75,提高空间利用率和 减少查询成本的折中,考虑到泊松分布,0.75的话碰撞最小。
加载因子如果为1,则会导致查询成本过高。
加载因子如果为0.5,则会导致空间过于浪费,还没有达到一定利用率就扩容了。
如果大于阈值就扩容,扩容为两倍。
Note:
虽然 HashMap 设计的非常优秀, 但是应该尽可能少的避免 resize(), 该过程会很耗费时间。
同时, 由于 hashmap 不能自动的缩小容量 因此,如果你的 hashmap 容量很大,但执行了很多 remove操作时,容量并不会减少。如果你觉得需要减少容量,请重新创建一个 hashmap。
ConcurrentHashMap解决线程安全问题,常用来做本地缓存
ConcurrentHashMap底层实现原理(JDK1.7 & 1.8)
HashMap?ConcurrentHashMap?相信看完这篇没人能难住你!
1.7采用分段锁的机制
理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
数据结构如下:
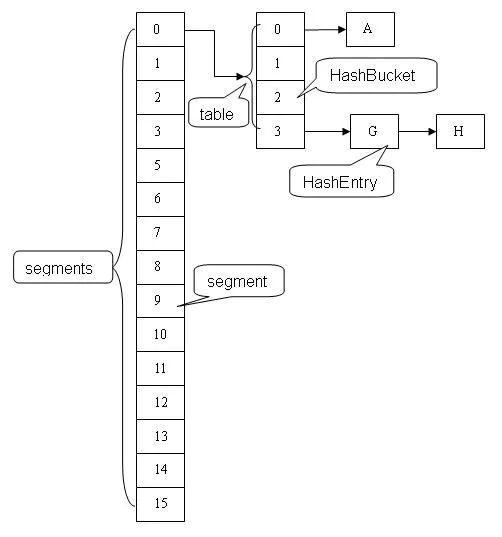
1.8采用CAS+Synchronized来保证并发更新的安全
CAS:
Compare and Swap(Set),比较数据,如果没有改变说明没有冲突,替换成功。否则替换失败。
面试通常的套路是:
谈谈你理解的 HashMap,讲讲其中的 get put 过程。(k-v存储的一个数据结构,然后能够较快的获取数据)(HashMap是链地址法,数组+链表的数据结构)
1.8 做了什么优化?:采用了红黑树,避免hash碰撞严重导致查询缓慢
是线程安全的嘛?:不是
不安全会导致哪些问题?:1.7之前会导致死循环、数据丢失;1.8之后会导致数据覆盖
如何解决?有没有线程安全的并发容器?:HashTable线程安全(效率低),ConcurrentHashMap。
ConcurrentHashMap 是如何实现的? 1.7、1.8 实现有何不同?为什么这么做?
1.7采用分段锁机制
1.8采用CAS+Synchronized来保证并发更新的安全,同时采用红黑树来提高速度
为什么8之后不用分段锁呢?